更新时间:2021-01-05 来源:黑马程序员 浏览量:

在Spark中,不同的RDD之间具有依赖的关系。RDD与它所依赖的RDD的依赖关系有两种类型,分别是窄依赖(narrow dependency)和宽依赖(wide dependency)。
窄依赖是指父RDD的每一个分区最多被一个子RDD的分区使用,即OneToOneDependencies。窄依赖的表现一般分为两类,第一类表现为一个父RDD的分区对应于一个子RDD的分区;第二类表现为多个父RDD的分区对应于一个子RDD的分区。也就是说,一个父RDD的一个分区不可能对应一个子RDD的多个分区。为了便于理解,我们通常把窄依赖形象的比喻为独生子女。当RDD执行map、filter及union和join操作时,都会产生窄依赖,如图1所示。
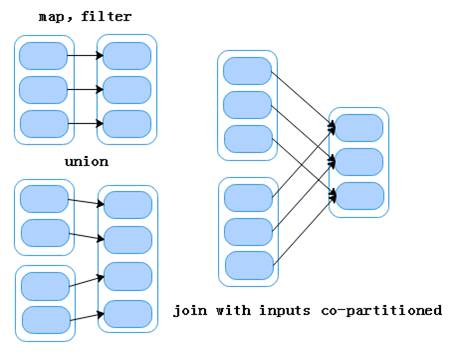
图1 Narrow Dependencies窄依赖
从图1可以看出,RDD做map、filter和union算子操作时,是属于窄依赖的第一类表现;而RDD做join算子操作(对输入进行协同划分)时,是属于窄依赖表现的第二类。这里的输入协同划分是指多个父RDD的某一个分区的所有Key,被划分到子RDD的同一分区,而不是指同一个父RDD的某一个分区,被划分到子RDD的两个分区中。当子RDD做算子操作,因为某个分区操作失败导致数据丢失时,只需要重新对父RDD中对应的分区(与子RDD相对应的分区)做算子操作即可恢复数据。
宽依赖是指子RDD的每一个分区都会使用所有父RDD的所有分区或多个分区,即OneToManyDependecies。为了便于理解,我们通常把宽依赖形象的比喻为超生。当RDD做groupByKey和join操作时,会产生宽依赖,如图2所示。
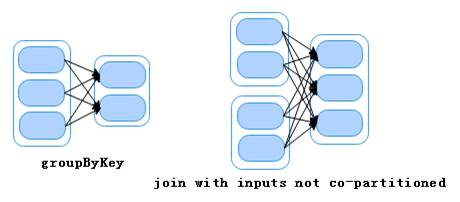
图2 Wide Dependencies宽依赖
从图2可以看出,父RDD做groupByKey和join(输入未协同划分)算子操作时,子RDD的每一个分区都会依赖于所有父RDD的所有分区。当子RDD做算子操作,因为某个分区操作失败导致数据丢失时,则需要重新对父RDD中的所有分区进行算子操作才能恢复数据。
需要注意的是,join算子操作既可以属于窄依赖,也可以属于宽依赖。当join算子操作后,分区数量没有变化则为窄依赖(如join with inputs co-partitioned,输入协同划分);当join算子操作后,分区数量发生变化则为宽依赖(如join with inputs not co-partitioned,输入非协同划分)。
猜你喜欢:
不同系统如何加载数据创建RDD?
















 JavaEE
JavaEE 鸿蒙应用开发
鸿蒙应用开发 集成电路应用开发
集成电路应用开发 人工智能开发
人工智能开发 AI+Linux云计算运维
AI+Linux云计算运维 Python+大数据开发
Python+大数据开发 跨境电商
跨境电商 AI+设计
AI+设计 软件测试
软件测试 新媒体+短视频
新媒体+短视频 HTML&JS+前端
HTML&JS+前端
















.jpg)