更新时间:2021-01-18 来源:黑马程序员 浏览量:

前期采集到的数据,或多或少都存在一些瑕疵和不足,比如数据缺失、极端值、数据格式不统一等问题。因此,在分析数据之前需要对数据进行预处理,包括数据的清洗、合并、重塑与转换。Pandas中专门提供了用于数据预处理的很多函数与方法,用于替换异常数据、合并数据、重塑数据等。
数据清洗是一项复杂且繁琐的工作,同时也是整个数据分析过程中最为重要的环节。数据清洗的目的在于提高数据质量,将脏数据(脏数据在这里指的是对数据分析没有实际意义、格式非法、不在指定范围内的数据)清洗干净,使原数据具有完整性、唯一性、权威性、合法性、一致性等特点。Pandas中常见的数据清洗操作有空值和缺失值的处理、重复值的处理、异常值的处理、统一数据格式等等。
空值一般表示数据未知、不适用或将在以后添加数据。缺失值是指数据集中某个或某些属性的值是不完整的,产生的原因主要有人为原因和机械原因两种,其中机械原因是由于机器故障造成数据未能收集或存储失败,人为原因是由主观失误或有意隐瞒造成的数据缺失。
一般空值使用None表示,缺失值使用NaN表示。Pandas中提供了一些用于检查或处理空值和缺失值的函数,其中,使用isnull()和notnull()函数可以判断数据集中是否存在空值和缺失值,对于缺失数据可以使用dropna()和fillna()方法对缺失值进行删除和填充,下面来一一介绍。
1. isnull()函数
isnull()函数的语法格式如下:
pandas.isnull(obj)
上述函数中只有一个参数obj,表示检查空值的对象,该函数会返回一个布尔类型的值,如果返回的结果为True,则说明有空值或缺失值,否则为False。(NaN或None映射到True值,其它内容映射到False)
接下来,通过一段示例来演示如何通过isnull()函数来检查缺失值或空值,具体代码如下:
In [1]: from pandas import DataFrame, Series import pandas as pd from numpy import NaN series_obj = Series([1, None, NaN]) pd.isnull(series_obj) # 检查是否为空值或缺失值 Out[1]: 0 False 1 True 2 True dtype:bool
上述示例中,首先创建了一个Series对象,该对象中包含1、None和NaN三个值,然后调用isnull()函数检查Series对象中的数据,数据为空值或缺失值就映射为True,其余值就映射为False。从输出结果看出,第一个数据是正常的,后两个数据是空值或缺失值。
2. notnull()函数
notnull()函数与isnull()函数的功能是一样的,都是判断数据中是否存在空值或缺失值,不同之处在于,前者发现数据中有空值或缺失值时返回False,后者返回的是True。
将上述调用isnull()函数的代码改为调用notnull()函数,改后的代码如下:
In [2]: from pandas import DataFrame, Series import pandas as pd from numpy import NaN series_obj = Series([1, None, NaN]) pd.notnull(series_obj) # 检查是否不为空值或缺失值 Out[2]: 0 True 1 False 2 False dtype: bool
上述示例中,通过notnull()函数来检查空值或缺失值,只要出现空值或缺失值就映射为False,其余则映射为True。从输出结果看出,索引0对应的数据为True,说明没有出现空值或缺失值,索引1和2对应的数据为False,说明出现了空值或缺失值。
3. dropna()方法
dropna()方法的作用是删除含有空值或缺失值的行或列,其语法格式如下:
dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
上述方法中部分参数表示的含义如下:
(1) axis:确定过滤行或列,取值可以为:
0或index:删除包含缺失值的行,默认为0。
1或columns:删除包含缺失值的列。
(2) how:确定过滤的标准,取值可以为:
any:默认值。如果存在NaN值,则删除该行或该列。
all:如果所有值都是NaN值,则删除该行或该列。
(3) thresh:c表示有效数据量的最小要求。若传入了2,则是要求该行或该列至少有两个非NaN值时将其保留。
(4) subset:表示在特定的子集中寻找NaN值。
(5) inplace:表示是否在原数据上操作。如果设为True,则表示直接修改原数据;如果设为False,则表示修改原数据的副本,返回新的数据。
假设,现在有一张关于书籍信息的表格,它里面有类别、书名和作者三列数据。其中,在索引为0的一行中书名为NaN,表明该位置的数据是缺失值,索引为1的一行中作者为None,表明该位置的数据是空值。如果删除这些空值和缺失值,那么删除前后的效果如图1所示。
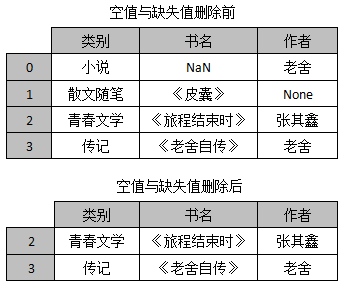
图1 删除空值/缺失值前后的表格
接下来,通过一个示例来演示如何使用dropna()方法删除空值和缺失值,具体代码如下。
In [3]: import pandas as pd
import numpy as np
df_obj = pd.DataFrame({"类别":['小说', '散文随笔', '青春文学', '传记'],
"书名":[np.nan, '《皮囊》', '《旅程结束时》', '《老舍自传》'],
"作者":["老舍", None, "张其鑫", "老舍"]})
df_obj
Out[3]: 类别 书名 作者
0 小说 NaN 老舍
1 散文随笔 《皮囊》 None
2 青春文学 《旅程结束时》 张其鑫
3 传记 《老舍自传》 老舍
In [4]: df_obj.dropna() # 删除数据集中的空值和缺失值
Out[4]:
类别 书名 作者
2 青春文学 《旅程结束时》 张其鑫
3 传记 《老舍自传》 老舍上述代码中,首先创建一个含有空值和缺失值的DataFrame对象,再让该对象调用dropna()方法将数据中的空值或缺失值进行过滤删除,只保留完整的数据。
从输出结果看出,所有包含空值或缺失值的行已经被删除了。
4. 填充空值/缺失值
填充缺失值和空值的方式有很多种,比如人工填写、特殊值填写、热卡填充等。Pandas中的fillna()方法可以实现填充空值或缺失值,其语法格式如下:
fillna(value=None, method=None, axis=None, inplace=False,limit=None, downcast=None, **kwargs)
上述方法中部分参数表示的含义如下:
(1) value:用于填充的数值。
(2) method:表示填充方式,默认值为None,另外还支持以下取值:
pad/ffill:将最后一个有效的数据向后传播,也就是说用缺失值前面的一个值代替缺失值。
backfill/bfill:将最后一个有效的数据向前传播,也就是说用缺失值后面的一个值代替缺失值。
(3) limit: 可以连续填充的最大数量,默认None。
注意:
method参数不能与value参数同时使用。
当使用fillna()方法进行填充时,既可以是标量、字典,也可以是Series或DataFrame对象。
假设现在有一张表格,它里面存在一些缺失值,如果使用一个常量66.0来替换缺失值,那么填充前后的效果如图2所示。
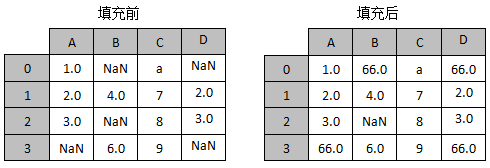
图2 填充缺失值示例
填充常数替换缺失值的示例代码如下。
In [5]: import pandas as pd
import numpy as np
from numpy import NaN
df_obj = pd.DataFrame({'A': [1, 2, 3, NaN],
'B': [NaN, 4, NaN, 6],
'C': ['a', 7, 8, 9],
'D':[ NaN, 2, 3, NaN]})
df_obj
Out[5]:
A B C D
0 1.0 NaN a NaN
1 2.0 4.0 7 2.0
2 3.0 NaN 8 3.0
3 NaN 6.0 9 NaN
In [6]: df_obj.fillna('66.0') # 使用66.0替换缺失值
Out[6]:
A B C D
0 1.0 66.0 a 66.0
1 2.0 4.0 7 2.0
2 3.0 66.0 8 3.0
3 66.0 6.0 9 66.0通过比较两次的结果可知,当使用任意一个有效值替换空值或缺失值时,对象中所有的空值或缺失值都将会被替换。
如果希望填充不一样的内容,例如,A列缺失的数据使用数字“4.0”进行填充,B列缺失的数据使用数字“5.0”来填充,那么填充前后的效果如图3所示。
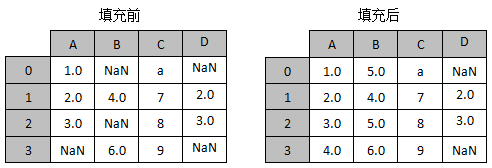
图3 指定填充列
调用fillna()方法时传入一个字典给value参数,其中字典的键为列标签,字典的值为待替换的值,实现对指定列的缺失值进行替换,具体示例代码如下。
In [7]: import pandas as pd
import numpy as np
from numpy import NaN
df_obj = pd.DataFrame({'A': [1, 2, 3, NaN],
'B': [NaN, 4, NaN, 6],
'C': ['a', 7, 8, 9],
'D': [NaN, 2, 3, NaN]})
df_obj
Out[7]:
A B C D
0 1.0 NaN a NaN
1 2.0 4.0 7 2.0
2 3.0 NaN 8 3.0
3 NaN 6.0 9 NaN
In [8]: df_obj.fillna({'A': 4.0, 'B': 5.0}) # 指定列填充数据
Out[8]:
A B C D
0 1.0 5.0 a NaN
1 2.0 4.0 7 2.0
2 3.0 5.0 8 3.0
3 4.0 6.0 9 NaN如果希望填充相邻的数据来替换缺失值,例如,A~D列中按从前往后的顺序填充缺失的数据,也就是说在当前列中使用位于缺失值前面的数据进行替换,填充前后的效果如图4所示。
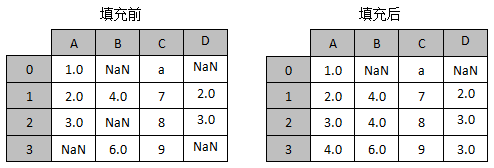
图4 前向填充示例
调用fillna()方法时将“ffill”传入给method参数,实现前向填充缺失的数据,具体示例代码如下。
In [9]: import pandas as pd
import numpy as np
from numpy import NaN
df = pd.DataFrame({'A': [1, 2, 3, None],
'B': [NaN, 4, None, 6],
'C': ['a', 7, 8, 9],
'D': [None, 2, 3, NaN]})
df
Out[9]:
A B C D
0 1.0 NaN a NaN
1 2.0 4.0 7 2.0
2 3.0 NaN 8 3.0
3 NaN 6.0 9 NaN
In [10]: df.fillna(method='ffill') # 使用前向填充的方式替换空值或缺失值
Out[10]:
A B C D
0 1.0 NaN a NaN
1 2.0 4.0 7 2.0
2 3.0 4.0 8 3.0
猜你喜欢:
















 JavaEE
JavaEE 鸿蒙应用开发
鸿蒙应用开发 集成电路应用开发
集成电路应用开发 人工智能开发
人工智能开发 AI+Linux云计算运维
AI+Linux云计算运维 Python+大数据开发
Python+大数据开发 跨境电商
跨境电商 AI+设计
AI+设计 软件测试
软件测试 新媒体+短视频
新媒体+短视频 HTML&JS+前端
HTML&JS+前端
















.jpg)