Sqoop工具操作简单,它提供了一系列的工具指令,来进行数据的导入、导出操作等。使用Sqoop解压包中bin目录下的“sqoop help”指令可以查看Sqoop支持的所有工具指令。查看全文>>


Kafka Streams是Apache Kafka开源项目的一个流处理框架,它是基于Kafka的生产者和消费者,为开发者提供了流式处理的能力,具有低延迟性、高扩展性、高弹性、高容错性的特点,易于集成到现有的应用程序中。查看全文>>

Spark SQL使用的数据抽象并非是RDD,而是DataFrame。在Spark 1.3.0版本之前,DataFrame被称为SchemaRDD。DataFrame使Spark具备了处理大规模结构化数据的能力。查看全文>>
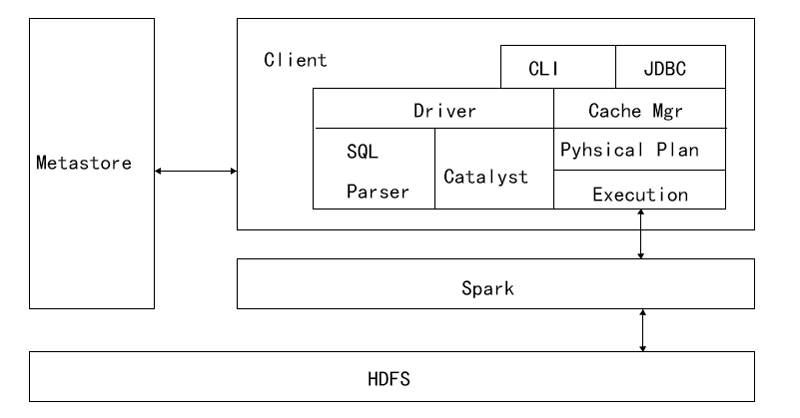
Spark SQL兼容Hive,这是因为Spark SQL架构与Hive底层结构相似,Spark SQL复用了Hive提供的元数据仓库(Metastore)、HiveQL、用户自定义函数(UDF)以及序列化和反序列工具(SerDes),通过下图深入了解Spark SQL底层架构。查看全文>>

Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个叫作Data Frame的编程抽象结构数据模型(即带有Schema信息的RDD),Spark SQL作为分布式SQL查询引擎,让用户可以通过SQL、DataFrame API和Dataset API三种方式实现对结构化数据的处理。查看全文>>
































